Published On Apr 8, 2024
In this tutorial, we'll explore how to create a local RAG (Retrieval Augmented Generation) pipeline that processes and allows you to chat with your PDF file(s) using Ollama and LangChain!
✅ We'll start by loading a PDF file using the "UnstructuredPDFLoader"
✅ Then, we'll split the loaded PDF data into chunks using the "RecursiveCharacterTextSplitter"
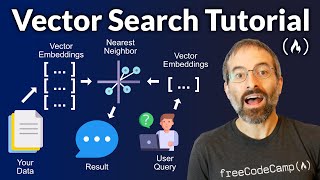
✅ Create embeddings of the chunks using "OllamaEmbeddings"
✅ We'll then use the "from_documents" method of "Chroma" to create a new vector database, passing in the updated chunks and Ollama embeddings
✅ Finally, we'll answer questions based on the new PDF document using the "chain.invoke" method and provide a question as input
The model will retrieve relevant context from the updated vector database, generate an answer based on the context and question, and return the parsed output.
TIMESTAMPS:
============
0:00 - Introduction
0:07 - Why you need to use local RAG
0:52 - Local PDF RAG pipeline flowchart
5:49 - Ingesting PDF file for RAG pipeline
8:46 - Creating vector embeddings from PDF and store in ChromaDB
14:07 - Chatting with PDF using Ollama RAG
20:03 - Summary of the RAG project
22:33 - Conclusion and outro
LINKS:
=====
🔗 GitHub repo: https://github.com/tonykipkemboi/olla...
Follow me on socials:
𝕏 → / tonykipkemboi
LinkedIn → / tonykipkemboi
#ollama #langchain #vectordatabase #pdf #nlp #machinelearning #ai #llm #RAG